Low-Cost, High Accuracy Solution Against Low Relevance in RAG Pipelines - A Case for Semantic Abstraction Layers
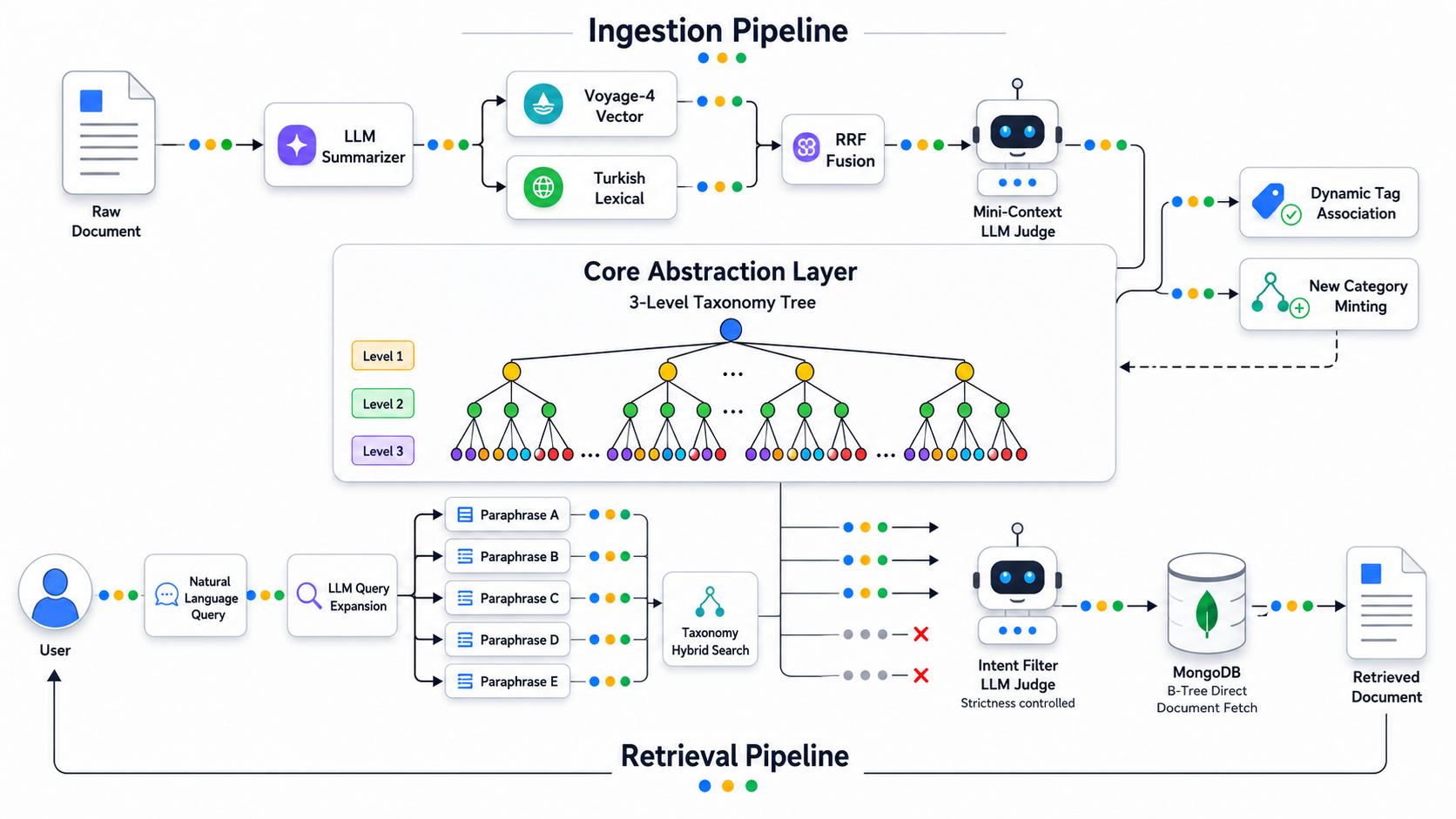
I have bypassed the scaling limitations of standard Retrieval-Augmented Generation (RAG) by inserting a semantic abstraction layer that is a living taxonomy.
Standard vector or hybrid search is a great baseline, but my experience showed me that it struggles with precise relevance at the very end of the retrieval pipeline. While many developers attempt to solve this by throwing expensive rerankers onto their pipelines or using an LLM as a judge across hundreds of retrieved documents to evaluate relevance, I think neither approach can both scale AND be precise with relevance. Rerankers often miss nuanced irrelevance, and forcing an LLM to evaluate raw, long-form documents rapidly depletes both context windows and budgets. Nothing about it helps with latency either.
Here is how I solved this problem, which I personally faced while developing Siyasentez.
TL;DR
Instead of connecting a search engine directly to a massive, noisy vector database, this architecture engineers a dynamic categorization taxonomy. By classifying documents at ingestion and forcing users to query this "living taxonomy" proxy instead of the raw corpora, the system achieves LLM-grade relevance filtration with standard database retrieval speeds, completely bypassing the massive token costs, context limits and relevance threshold ambiguity of traditional RAG.
1. The Bottleneck: Why Standard RAG Falls Short
In a traditional RAG pipeline, a user's query is vectorized and compared directly against the embeddings of the underlying documents. Even with hybrid search (combining vector similarity with lexical keyword matching), the search engine inevitably returns noise.
To filter out this noise, the industry standard relies on secondary validation:
-
Reranking Models: Often computationally expensive and surprisingly insufficient for complex semantic filtration.
-
LLM as a Judge: Highly accurate, but financially unviable. Asking an LLM to read through dozens of dense, long-form documents to determine relevance is slow and astronomically expensive.
2. Data Ingestion: Building the Living Proxy
Instead of directly querying the documents, the pipeline builds and maintains an ever-growing, 3-level categorization taxonomy. This taxonomy acts as a highly compressed semantic proxy for the entire knowledge base.
The Smart Ingestion Workflow:
-
Summarization & Hybrid Match: When a new document enters the system, if it doesn't have a summary/title already, it gets summarized. This summary is used to run a hybrid search against the existing taxonomy. I use MongoDB as my database as it's very convenient for dealing with unstructured data and for any purpose related to AI pipeline infrastructure such as (auto) embedding, vector search, BM25 and serving MCPs. Search results are cleanly merged via Reciprocal Rank Fusion (RRF).
-
LLM as a Judge: The top n candidate categories are sent to the Judge LLM. Because it is evaluating short, concise category definitions against one document's summary rather than massive documents, the token count, and thus the cost, is comparatively insignificant.
-
Living Taxonomy: If the Judge LLM determines that the existing categories do not adequately cover the document's concepts, it generates new ones. The taxonomy organically grows to meet the complexity of the data.
The Byproduct: Because every document is now neatly mapped to this taxonomy, you instantly gain a structured, highly organized dashboard element, empowering users with manual filtering capabilities that standard RAG completely lacks. Fundamentally, I find this very similar to the logic behind GraphRAG, but since I don't find it feasible for this project, this light version of it gives me what I need.
3. User Retrieval: Precision at a Fraction of the Cost
When a user interacts with the system, their query never actually touches the (now) 25,000-document-sized corpus directly.
The Proxy Search Workflow:
-
Query Expansion: The user's initial search term is multiplied by an LLM into a few slightly different, highly articulated expressions/paraphrases. This ensures the user's true objective is captured with its multiple potential facets, while protecting the flow from human error e.g. flawed wording.
-
Taxonomy Search: These expressions execute a parallel hybrid search strictly against the taxonomy documents.
-
Relevance Filtration: The LLM judges these retrieved categories against the user's intent. Strictness parameters allow the system to prune out anything that isn't a definitive match.
-
Document Fetching: Once the exact taxonomy codes are validated, the system simply performs a highly efficient database lookup to fetch the actual legislative documents tagged with those codes, pulling from parallel activity collections.
4. The Economics of the Architecture
The fundamental gimmick of this workflow lies in its economic model.
Standard RAG isn't actually that costly, but deciding where to draw the line is a complex, probability problem. I love how little room for a mistake is there when the problem space is restricted, such as asking whether a document is relevant to a search term.
Another thing I love is working with frontier models from China when I'm not processing personal data.
My approach is, at its core, just shifting the heavy lifting to ingestion time. All documents must be processed and categorized upfront, meaning there is an initial capitalization cost. However, because the retrieval phase only requires the LLM to process short query expansions and lightweight taxonomy tags, the operational cost per user query plummets. In the Siyasentez ecosystem, the math works out to a break-even point that is as low as 400 user queries. Beyond that threshold, this taxonomy-driven approach operates at a fraction of the cost of standard RAG, while delivering heavily vetted, conceptually exact results that simply cannot break the bank.