Standart RAG Yetersiz Kaldığında Düşük Maliyete Yüksek Hassiyetli Bir Çözüm: Semantik Soyutlama Katmanı
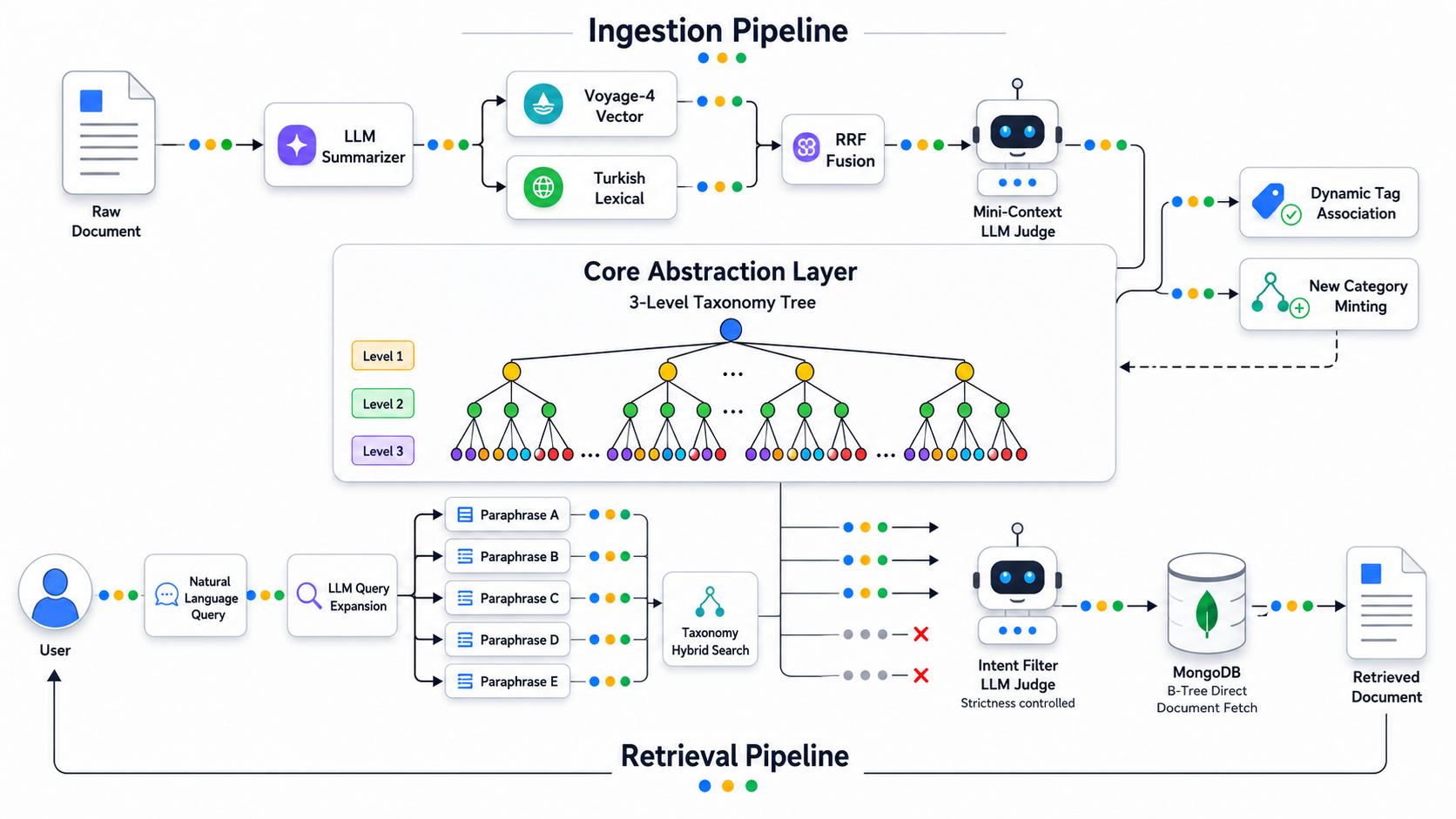
Standart Retrieval-Augmented Generation (RAG) sistemlerinin ölçekleme kısıtlamalarını, "yaşayan taksonomi" adını verdiğim semantik bir soyutlama katmanı ekleyerek aştım.
Standart vektör veya hibrit arama iyi bir başlangıç noktası oluştursa da deneyimlerim, bu yöntemin retrieval pipeline'ının son aşamasında döndürülen dökümanların her zaman belli bir alaka seviyesini tutturmakta zorlandığını gösterdi, yani dökümanlar alaka bazında doğru sıralanıyor ancak alaka eşiği her zaman doğru belirlenemiyor. Hangi noktadan sonraki dökümanlara ihtiyacımız olmadığı isabetli belirlenemiyor. Pek çok geliştirici bu sorunu pahalı reranker'lar ekleyerek ya da yüzlerce belge üzerinde alaka değerlendirmesi yapan bir LLM kullanarak çözmeye çalışır ancak bu yaklaşımların hiçbirinin hem ölçeklenebilir hem de hassas olamayacağını düşünüyorum. Reranker'lar nüanslı anlamsallıkları kaçırabilir; ham ve uzun belgeleri değerlendirmesi için bir LLM'i zorlamak ise hem bağlam pencerelerini hem de bütçeleri hızla tüketir. Üstelik bu yöntemlerin hiçbiri bu işlemin çok uzun sürmesi sorununa da çözüm getirmez.
Siyasentez'i geliştirirken bizzat karşılaştığım bu sorunu nasıl çözdüğümü aşağıda anlatıyorum.
Özet
Bir arama motorunu doğrudan büyük ve gürültülü bir vektör veritabanına bağlamak yerine, bu mimari dinamik bir sınıflandırma taksonomisi inşa eder. Belgeler sisteme alınırken sınıflandırılır ve kullanıcılar ham corpus'a değil, bu "yaşayan taksonomi" proxy'sine sorgu göndermeye yönlendirilir. Böylece sistem; geleneksel RAG'ın yol açtığı yüksek token maliyetlerini, bağlam penceresi kısıtlamalarını ve alaka eşiği belirsizliğini tamamen devre dışı bırakarak standart veritabanı retrieval hızlarında LLM düzeyinde alaka filtresi sağlar.
1. Standart RAG Neden Yetersiz Kalır?
Geleneksel bir RAG pipeline'ında kullanıcının sorgusu vektöre dönüştürülür ve doğrudan belgelerin embedding'leriyle karşılaştırılır. Hibrit arama (vektör benzerliğiyle kelime eşleştirmenin birleşimi) kullansanız dahi arama motoru kaçınılmaz olarak gürültülü sonuçlar döndürür.
Bu gürültüyü filtrelemek için sektörde yaygın olarak iki yöntem kullanılabilir:
- Reranking Modelleri: Hesaplama maliyeti yüksek ve karmaşık semantik filtreleme için yetersiz.
- Yargıç LLM: İstenen filtrelemeyi yapması için tüm sonuçlar LLM'e gönderilir. Yüksek doğruluk sağlar ancak finansal açıdan sürdürülemez. Onlarca uzun ve yoğun belgeyi okuyarak alaka değerlendirmesi yapması için bir LLM'e başvurmak hem yavaş hem de son derece pahalıdır.
2. Yaşayan Proxy'yi İnşa Etmek
Belgeleri doğrudan sorgulamak yerine, pipeline sürekli büyüyen 3 düzeyli bir sınıflandırma taksonomisi oluşturur ve bu taksonomi aynı zamanda tüm bilgi tabanının yüksek düzeyde sıkıştırılmış semantik bir proxy'si olarak işlev görür.
Smart Ingestion İş Akışı:
- Özetleme ve Hibrit Eşleştirme: Sisteme yeni bir belge girdiğinde, eğer belgenin özeti veya başlığı yoksa önce özetlenir. Bu özet, mevcut taksonomi üzerinde hibrit arama yapmak için kullanılır. Veritabanı olarak MongoDB tercih ediyorum; çünkü yapılandırılmamış verilerle çalışmak ve otomatik embedding, vektör arama, BM25 ve MCP sunumu gibi AI pipeline altyapısı gerektiren her türlü kullanım senaryosu için son derece elverişli. Arama sonuçları Reciprocal Rank Fusion (RRF) yöntemiyle birleştirilir.
- Yargıç LLM: En iyi n aday kategori, Judge LLM'e gönderilir. LLM bu aşamada uzun belgeler yerine yalnızca kısa ve öz kategori tanımlarını tek bir belge özetiyle karşılaştırdığından token sayısı, dolayısıyla maliyet, oldukça düşük kalır.
- Yaşayan Taksonomi: Judge LLM mevcut kategorilerin belgenin kavramlarını yeterince karşılamadığına karar verirse yeni kategoriler üretir. Taksonomi, verinin karmaşıklığına ayak uyduracak şekilde organik olarak büyür.
Yan Kazanım: Her belge bu taksonomiye düzenli biçimde eşlendiğinden, kullanıcılara standart RAG'ın hiçbir zaman sunamadığı manuel filtreleme imkânı tanıyan yapılandırılmış ve son derece organize bir pano öğesi kendiliğinden ortaya çıkar. Bu mantığın özünde GraphRAG'ların yaklaşımıyla güçlü bir benzerlik görüyorum; ancak bu proje için GraphRAG'ı uygulamak fizibıl olmadığından, ihtiyacım olanı bu hafif versiyon karşılıyor.
3. User Retrieval: Ufak Maliyet, Yüksek Hassasiyet
Kullanıcı sistemle etkileşime geçtiğinde sorgusu, şu anda 25.000 belgeyi barındıran veritabanıyla doğrudan etkileşime girmez.
Proxy Arama İş Akışı:
- Sorgu Genişletme: Kullanıcının başlangıçtaki arama terimi, bir LLM tarafından birbirinden hafif farklı, daha nitelikli şekilde tekrar ifade edilmiş birkaç varyanta dönüştürülür. Bu sayede kullanıcının gerçek amacı birden fazla potansiyel açıdan yakalanırken hatalı ifade gibi insan kaynaklı hatalardan da korunulur.
- Taksonomi Araması: Bu ifadeler, yalnızca taksonomi belgeleri üzerinde paralel hibrit arama çalıştırır.
- Alaka Filtresi: LLM, retrieval edilen kategorileri kullanıcının amacına göre değerlendirir. Katılık parametreleri sayesinde kesin eşleşme olmayan her şey ayıklanabilir.
- Belge Çekme: Taksonomi kodları doğrulandıktan sonra sistem, bu kodlarla etiketlenmiş belgeleri paralel aktivite koleksiyonlarından çekerek son derece verimli bir veritabanı araması gerçekleştirir.
4. Mimarinin Ekonomisi
Bu iş akışının temel cazibesi ekonomik modelinde yatıyor.
Standart RAG aslında o kadar da maliyetli değildir; ancak çizgiyi nerede çizeceğinize karar vermek karmaşık bir olasılık problemidir. Problem uzayını kısıtladığınızda, örneğin bir belgenin belirli bir arama terimiyle alaka düzeyini sorguladığınızda, hata payının bu denli küçük olmasını çok seviyorum.
Kişisel veri işlemediğim durumlarda Çinli frontier modellerle çalışmaktan da büyük keyif alıyorum.
Yaklaşımımın özünde ağır işi ingestion aşamasına kaydırmak yatıyor. Tüm belgeler önceden işlenip kategorize edilmeli; bu da başlangıçta nispeten yüksek bir maliyet anlamına geliyor. Ancak retrieval aşaması LLM'in yalnızca kısa sorgu genişletmeleri ve hafif taksonomi etiketleri işlemesini gerektirdiğinden kullanıcı sorgusu başına operasyonel maliyet önemli ölçüde düşüyor. Siyasentez ekosisteminde yaptığım hesaplamalar, başabaş noktasının yalnızca 400 kullanıcı sorgusu kadar düşük olduğunu ortaya koyuyor. Bu eşiğin ötesinde, taksonomi odaklı yaklaşım standart RAG maliyetinin çok küçük bir bölümüyle çalışırken bütçeyi hiçbir şekilde zorlamayan, titizlikle denetlenmiş ve kavramsal açıdan isabetli sonuçlar üretiyor.